Understand every Chinese character at a glance
Radicals, usage, SRS, strokes, reading practice — all in one app.



42,000+
Audio Recordings
200,000+
Example Sentences
161,000
Dictionary Entries
60,000+
Decompositions
Core Modules
Engineered for how characters are actually constructed
Navigate 3,145 characters by radical taxonomy
Query any HSK character and view its radical decomposition, phonetic series, and structural relatives — mapped across the full standard.
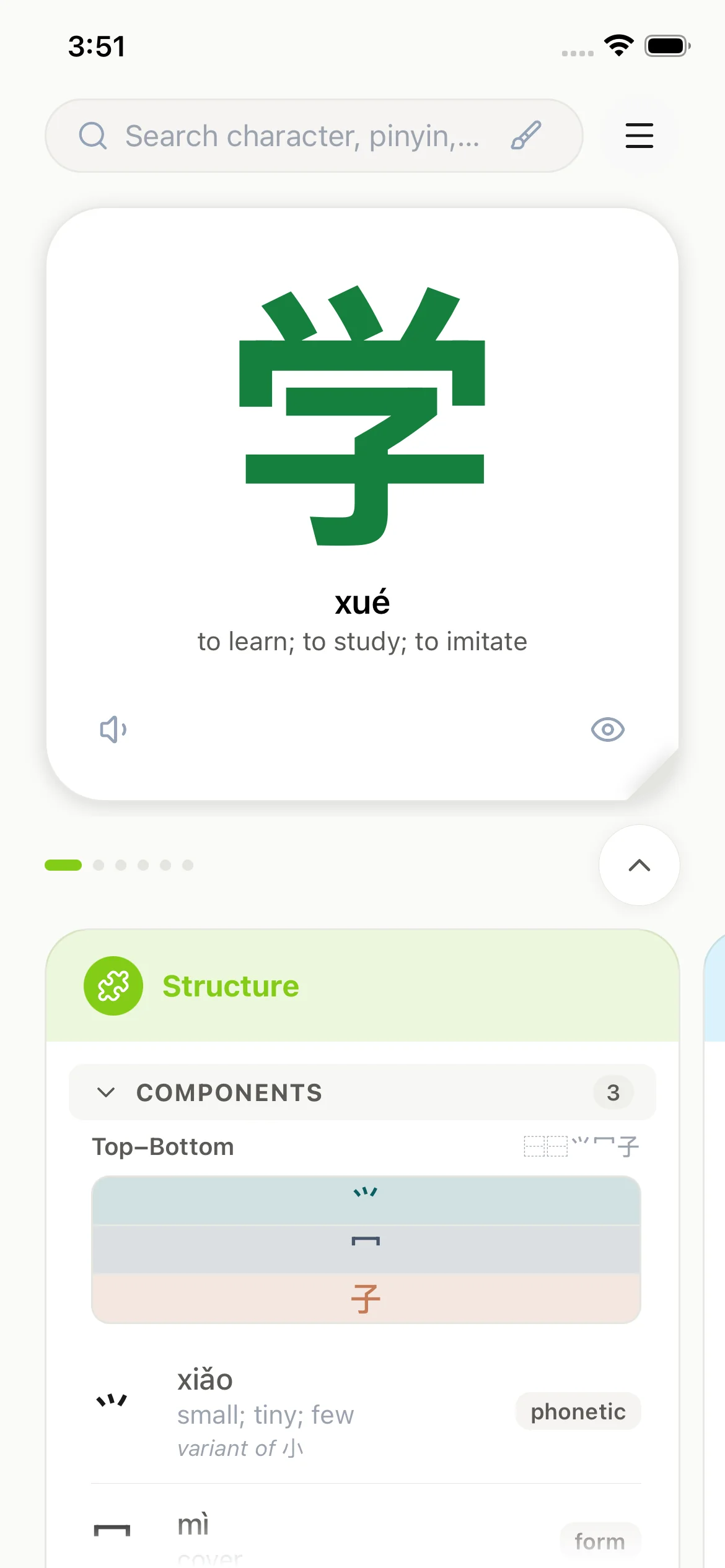
Six data panels per entry
Each character opens a colour-coded carousel — Structure, Words, Usage, Family, Sentences, and Mastery — presenting composition, frequency data, and contextual usage in one view.
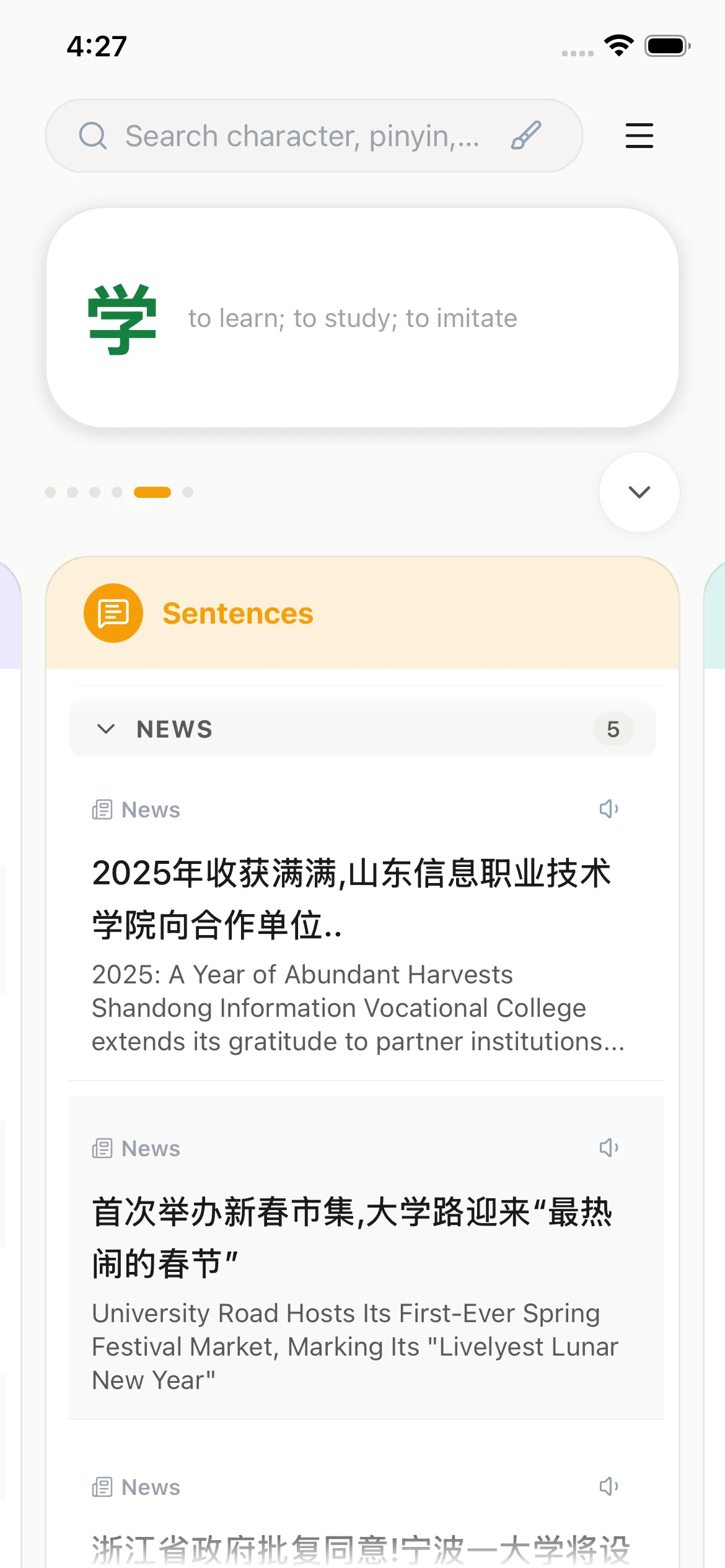
Read real Chinese sentences in context
Practice reading with sourced sentences drawn from news, community content, and curated corpora — each with aligned pinyin and English translations to build comprehension naturally.

Daily: 月
moon; monthAnimated stroke-order playback
Step through precise stroke sequences for all 3,145 characters on a traditional rice grid (田字格) with frame-by-frame controls.
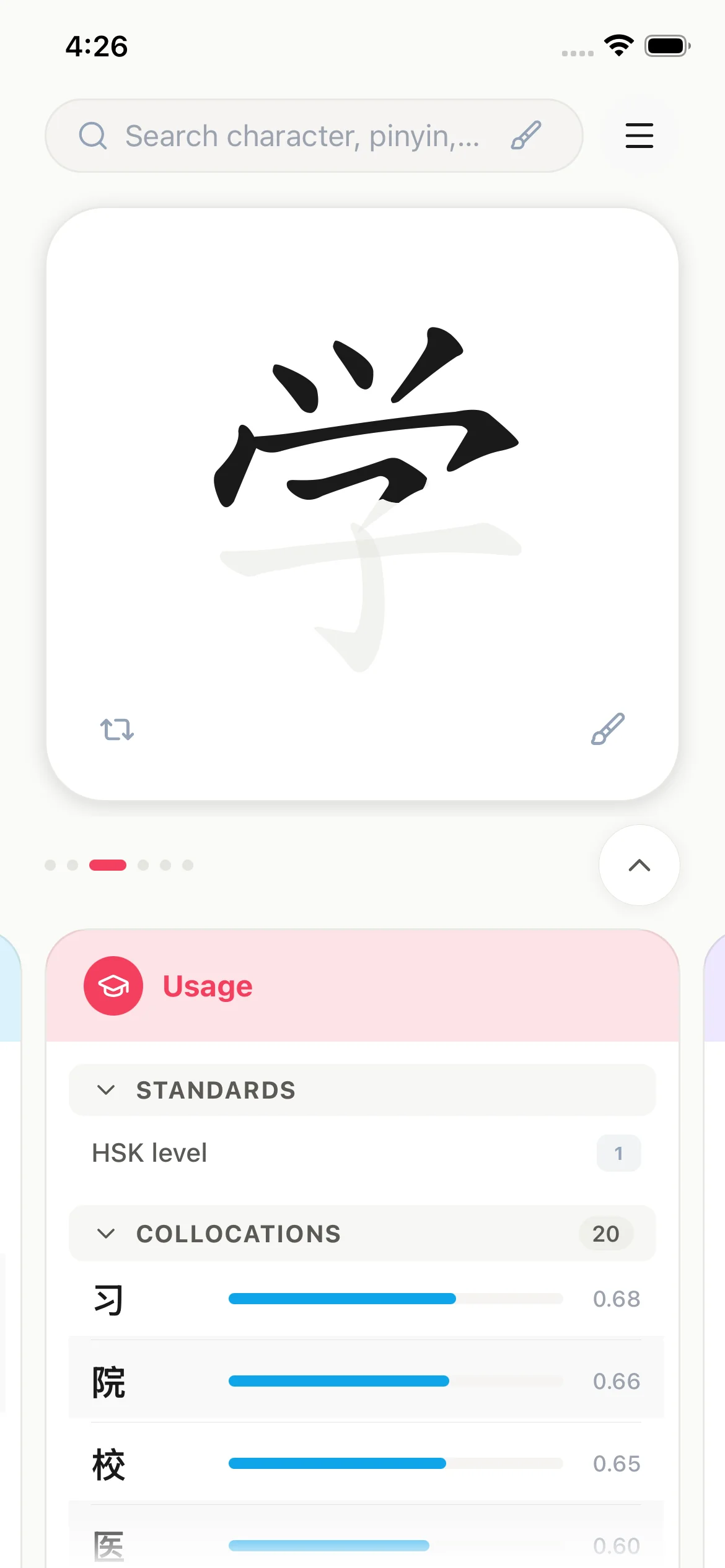
Six-bucket spaced repetition
A six-stage scheduling algorithm surfaces characters at optimal intervals. Grade each recall with a swipe — the system recalibrates spacing automatically.

Why HanziFeed
Conventional tools list characters. They don't expose the system behind them.
Chinese characters are not arbitrary — they are composed from a finite set of radicals, phonetic components, and structural patterns.
Conventional Tools
- ✕ Isolated character look-ups with no structural context
- ✕ Stroke drilling without decomposition data
- ✕ Flat word lists with no frequency grading
The HanziFeed Instrument
- ✓ Radical-level decomposition and structural mapping
- ✓ Six data panels per entry with cross-referenced context
- ✓ Frequency-tiered word lists and NPMI-ranked collocations
- ✓ Spaced-repetition scheduling calibrated to recall performance
Once the underlying structure is visible, thousands of characters resolve from noise into a navigable system. HanziFeed is engineered around this principle — decompose, analyze, trace, retain, repeat.
Product Features
Under the surface
Four-Voice Audio Engine
42,000+ recordings across four native speakers — character, sentence, and word-level playback.
Sentence Corpus
200,000+ sourced sentences from news, community, and generated corpora — with aligned pinyin and translations.
Script Toggle
Switch between simplified and traditional character forms instantly. Both variants are indexed on every entry.
Tone-Mapped Pinyin
Pinyin is colour-coded by tone across the interface, reinforcing tonal patterns during every interaction.
HSK-Graded Sets
Complete coverage of HSK levels 1 through 7–9. Begin at any tier or construct custom graded sets.
Multi-Axis Search
Query by hanzi, pinyin, English gloss, or radical. Results resolve as you type.
Custom Collections
Assemble character sets by textbook chapter, topic, or personal criteria — fully portable across the app.
Offline Architecture
The complete dataset downloads on first launch. No network dependency — operate on a subway, a flight, anywhere.
Get HanziFeed
Available now on iOS and Android.
The core instrument is free — full character browsing, graded sets, and spaced repetition at no cost. A Pro tier adds cloud sync, additional voice data, and extended analytics.